by Kai Wedekind
“I don’t see any reason why we would(n’t) use the Speech Recognition API,
we could use other API’s also, there are a lot of API’s out there.” — D.T.
Did you have ever wonder, if it is possible to use and navigate a website with only voice commands? — No? — Is that possible? — Yes!
In year 2012 the W3C Community introduced the Web Speech API specification. The goal was to enable speech recognition and -synthesis in modern browsers. It is July 2018, and the WebSpeech API is still a working draft and only available in Chrome and Firefox (Not supported by default, but can be enabled).
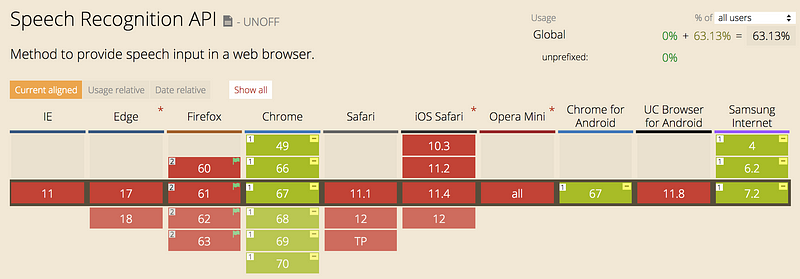
You can almost say that Chrome is the only browser that has implemented the W3C specification, using Google’s speech recognition engines.
As a web developer I was excited about the specification, as it opens up a whole new world of opportunities for web apps and new interaction features in existing apps. And since Google opened its own speech recognition engine to support that API, we are able to incorporate one of the best speech recognition technologies out there. At this point — the API is free in conjunction with Google, but there is no guarantee it will continue to be in the future.

The HTML5 Speech Recognition API allows JavaScript to have access to a browser’s audio stream and to convert it to text. I’m going to show you how to use the web speech API so that you can invite your users to talk with your current or future web application.
Basic usage
The speech recognition interface lives on the browser’s window object as SpeechRecognition in Firefox and as webkitSpeechRecognition in Chrome.
Start by setting the recognition interface to SpeechRecognition (regardless of the browser) using:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
After that, make sure that the speech recognition API is supported by your browser.
if ('SpeechRecognition' in window) {
// speech recognition API supported
} else {
// speech recognition API not supported
}
The next step is to create a new speech recognition object.
const recognition = new window.SpeechRecognition();
This recognition object has many properties, methods and event handlers.
Properties:
- recognition.grammars
- recognition.lang
- recognition.continuous
- recognition.interimResults (default: false)
- recognition.maxAlternatives (default: 1)
- recognition.serviceURI
Methods:
Event handlers:
- recognition.onaudiostart
- recognition.onaudioend
- recognition.onend
- recognition.onerror
- recognition.onnomatch
- recognition.onresult
- recognition.onsoundstart
- recognition.onsoundend
- recognition.onspeechstart
- recognition.onspeechend
- recognition.onstart
With that in mind, we can create our first speech recognition example:
const recognition = new window.SpeechRecognition();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript; }
recognition.start();
This will ask the user to allow the page to have access to the microphone. If you allow access you can start talking and when you stop, the onresult event handle will be fired, making the results of the speech capture available as a JavaScript object.
The onresult event handler returns a SpeechRecognitionEvent with a property results which is a two-dimensional array. I took the first object of this matrix which contains the transcript property. This property holds the recognized speech in text format. If you haven’t set the properties interimResults or maxAlternatives then you will get only one result with only one alternative back.
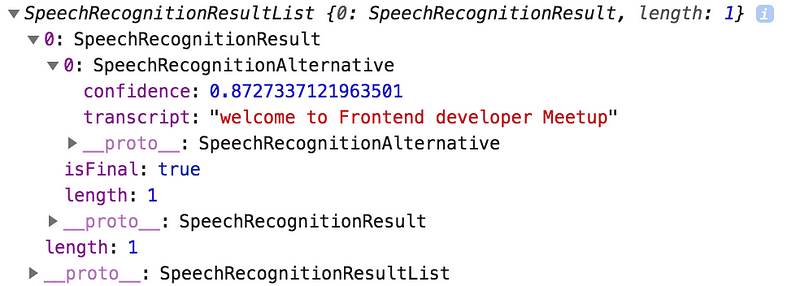
The first dimension are the interim results, so when the recognizer is recognizing the speech while you are speaking, it captures the partial parts of that recognition.
Streaming results
You have two choices for capturing results; you can either wait until the user has stopped talking or have results pushed to you when they are ready. If you set the recognition.interimResults = true, then your event handler is going to give you a stream of results back, until you stop talking.
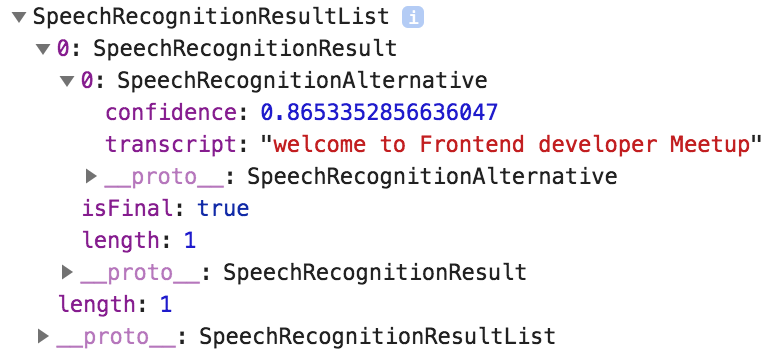
This means you can start to render results before the user has stopped talking. With the same sentence like above “Welcome to Frontend developer meetup” I got the following interim results back.

The last streamed interim result has an isFinal = true flag, that indicated that the text recognition has finished.
The other flag is maxAlternatives (default: 1), which gives you the number of alternatives of the speech recognition back.
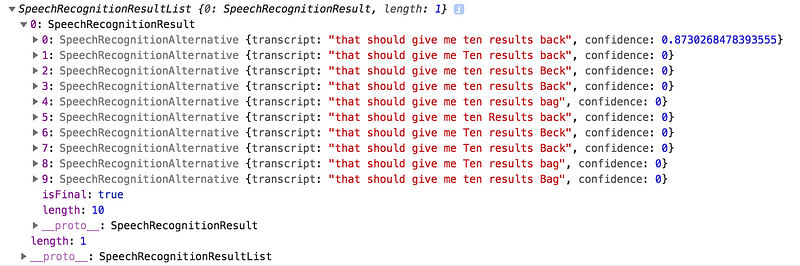
Each speech recognition result and alternative has a confidence value which tells you how confident the recognition was. In my experience, the first alternative always had the highest confidence.
If you’ve tried the examples above, you probably noticed that when you stopped speaking, the recognition engine stopped recognizing. That’s because there is a flag, recognition.continuous which is set to false by default. If you set recognition.continuous = true , the recognition engine will treat every part of your speech as an interim result.
Because of this, I changed the onresult event handler so that it read the elements of the results array each time I said something. As a result the onresult event handler will be called every time I finished a sentence.
Handling accents and languages
If your users are speaking a language other than English, you can improve their results by specifying a language parameter withrecognition.lang. To recognize German you’d use recognition.lang = "de-DE" or for a British accent recognize.lang = "en-GB". The default language isen-US.
Accessibility
What if you want to add voice commands to your website? Sometimes it is just easier to say what you want to do. Speech recognition therefore can help you with searching the web, dictating emails, controlling the navigation through your app. Many people with physical disabilities who cannot use the keyboard or mouse rely on speech recognition to use the computer. To make that possible, websites and applications need to be properly developed to do that. Content must be properly designed and coded so that it can be controlled by voice. Labels and identifiers for controls in code need to match their visual presentation, so that it is clear which voice command activates a control. Speech recognition can additionally help lots of people with temporary limitations too, such as an injured arm.
Speech recognition can be used to fill out form fields, as well as to navigate to and activate links, buttons, and other controls. Most computers and mobile devices nowadays have built-in speech recognition functionality. Some speech recognition tools allow complete control over computer interaction, allowing users to scroll the screen, copy and paste text, activate menus, and perform other functions.
It is not an easy task, but not impossible. You have to manage all callbacks, starting, and stopping of the speech recognition, and the handling of errors in the event that something goes wrong.
To handle all speech commands and actions, I’ve decided to write a library with the name AnyControl. AnyControl is a small JavaScript SpeechRecognition library that lets you control your site with voice commands. It is built on top of Webkit Speech API.
AnyControl has no dependencies, just 3 KB small, and is free to use and modify.
Security
If your are using the Speech Recognition API, it is most likely that your browser is going to ask you for permission to use your microphone. With pages hosted on https you are only asked once; you don’t have to repeatedly give access. When you use the http protocol the browser is going to ask you every single time it wants to make an audio capture.
This seems like a security vulnerability in the sense that an application can record audio on an https hosted page once a user has authorized it. The Chrome API interacts with Google’s Speech Recognition API, so all of the data is going to Google and whoever else might be listening.
In context of JavaScript the entire page has access to the output of the audio capture, so if your page is compromised the data from the instance could be read.
Conclusion
The Speech Recognition API is very useful for data entry, website navigation and commands. It is interesting to see that it is possible to capture a conversation to have something like an instant transcript. There are definitely some security concerns with this API where a HTTPS Web Application could start listening at any time after you have approved access. Therefore, if you use the speech recognition API, use it with caution.
If you would like to see more, check out my website www.kaiwedekind.com
References
Kai Wedekind
Software Engineer. Entrepreneur. Lifetime Learner.
codeburst
Bursts of code to power through your day. Web Development articles, tutorials, and news.