Get familiar with function-as-a-service (FaaS), deploy a demo on a AWS Lambda serverless computing platform, hook up a MongoDB database-as-a-service to a serverless REST API, and more.

Serverless architecture is a cloud computing execution model where a cloud provider like AWS, Azure or Google Cloud is used to deploy backend or server-side code. In comparison to traditionally deployed web applications, in serverless architecture, the developer does not has to maintain the servers or the infrastructure. They only have to pay a subscription to the third party vendor whereas the vendor is responsible to handle the operation of the backend logic of a server along with scalability, reliability, and security.
There are two ways a serverless architecture can be implemented in order to deploy your server side code. First one is Backend as a Service or BaaS. A good example of this is Firebase Firebase Venezuela which you can often see in conjunction between a web or a mobile application to a database or providing user authentication.
What we are going to focus in this article is called Function as a Service or FaaS. With FaaS, the server code is run inside containers that are usually triggered by common events such as HTTP requests from client, database operations, file uploads, scheduled events and so on. The code on the cloud provider that is deployed and getting executed is in the form of a function.
In FaaS, these functions are deployed in modular form. One function corresponds to each operation, thus eliminating the rest of the code and time spent on writing boilerplate code for setting up a server and data models. These modular functions can further be scaled automatically and independently. This way, more time can be spent on writing the logic of the application that a potential user is going to interact with. You do not have to scale for the entire application and pay for it. Common use cases of FaaS so far have been implemented are scheduled tasks (or cron jobs), automation, web applications, and chatbots.
Common FaaS service platform providers are:
- AWS Lambda
- Google Cloud Functions
- Microsoft Azure Functions
- Apache OpenWhisk
In the following tutorial, we are going to create a demo to deploy on a serverless infrastructure provider such as AWS Lambda.
What is AWS Lambda?
In order to build and deploy a backend function to handle a certain operation, I am going to start with setting up the service provider you are going to use to follow this article. AWS Lambda supports different runtimes such as Node.js, Java, Python, .NET Core and Go for you to execute a function.
The function runs inside a container with a 64-bit Amazon Linux AMI. You might be thinking, ‘why I am telling you all of this?’ Well, using serverless for the first time can be a bit overwhelming and if you know what you are getting in return, that’s always good! More geeky stuff is listed below.
- Memory: 128MB — 3008MB
- Ephemeral disk space: 512MB
- Max execution duration: 300 seconds
- Compressed package size: 50MB
- Uncompressed package size: 250MB
The execution duration here means that your Lambda function can only run a maximum of 5 minutes. This does mean that it is not meant for running longer processes. The disk space is the form of a temporary storage. The package size refers to the code necessary to trigger the server function. In case of Node.js, this does mean that any dependencies that are being imported into our server (for example, node_modules/ directory).
A typical lambda function in a Node.js server will look like below.

In the above syntax, handlerFunction is the name of our Lambda function. The event object contains information about the event that triggers the lambda function on execution. The context object contains information about the runtime. Rest of the code is written inside the Lambda function and at last a callback is invoked with an error object and result object. We will learn more about these objects later when are going to implement them.
Setting up AWS Lambda
In order to setup a Lambda function on AWS, we need to first register an account for the access keys. Use your credentials to login or signup a new account on console.amazon.com and once you are through the verification process you will be welcomed by the following screen.
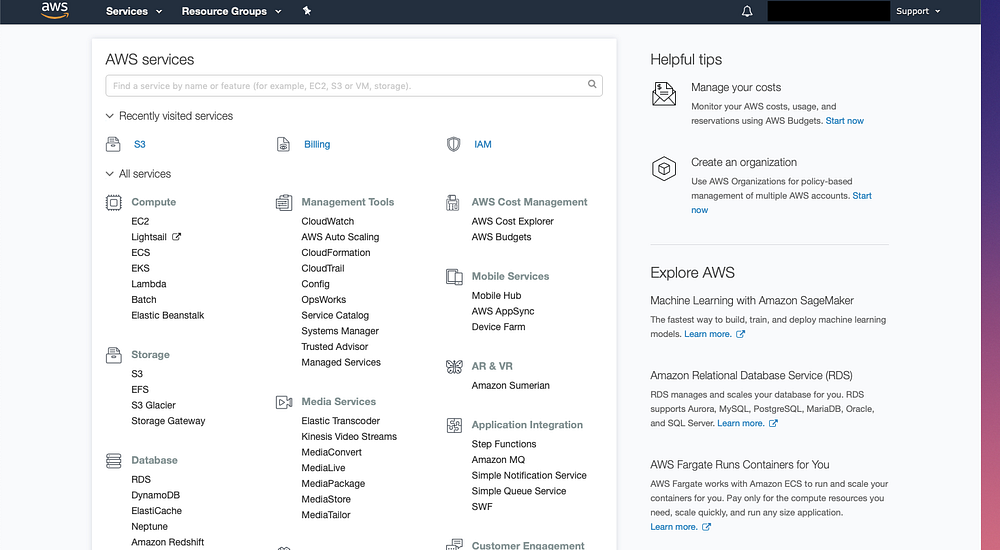
To get the keys and permissions in order to deploy a function, we have to switch to Identity and Access Management (IAM). Then go to Users tab from the left hand sidebar and click on the button Add user. Fill in the details in the below form and do enable Access Type > Programmatic Access.
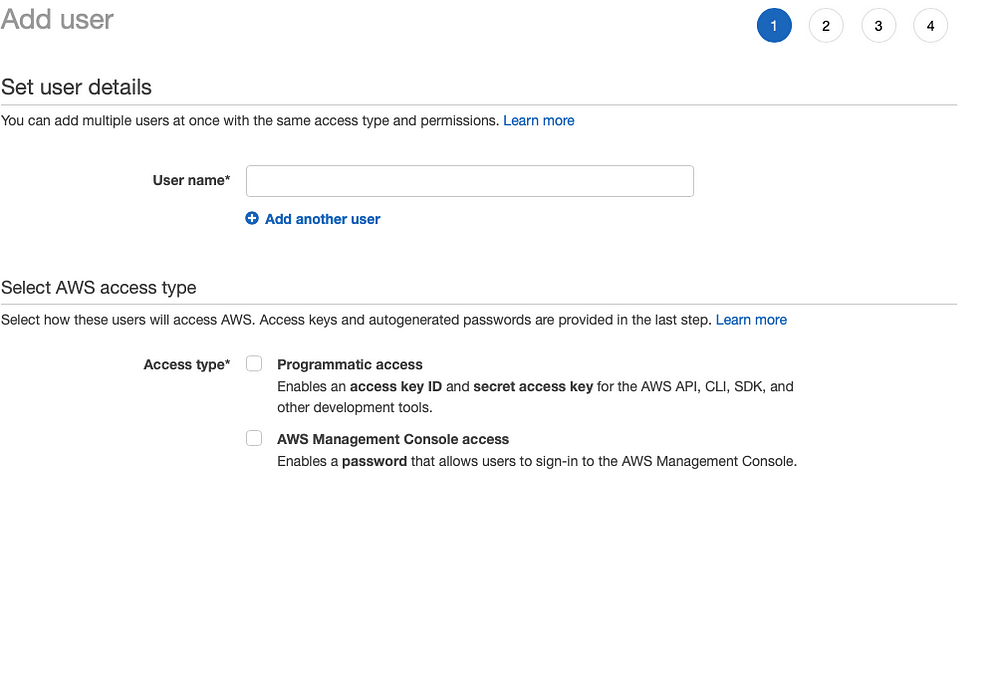
Then on the next page, select Attach Existing Policies Directly and then select a policy name AdministratorAccess.

Click Next: Review button and then click Create User button when displayed. Proceeding to the next step you will see the user was created. Now, and only now, will you have access to the users Access Key ID and Secret Access Key. This information is unique for every user you create.
Creating a Serverless Function
We are going to use install an npm dependency first to proceed and scaffold a new project. Open up your terminal and install the following.
npm install -g serverless
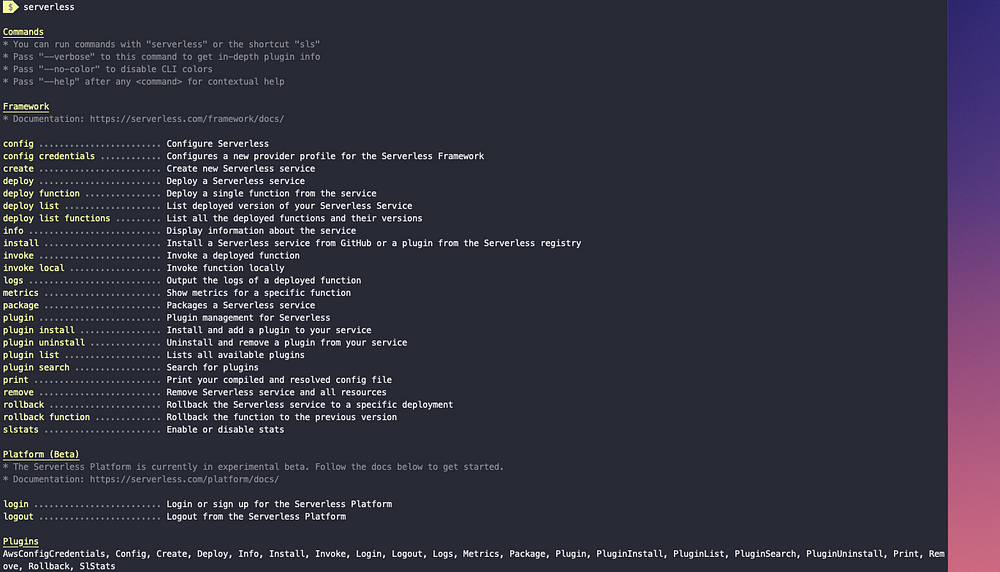
Once installed, we can run the serverless framework in the terminal by running the command:
serverless
Or use the shorthand sls for serverless. This command will display all the available commands that come with the serverless framework.
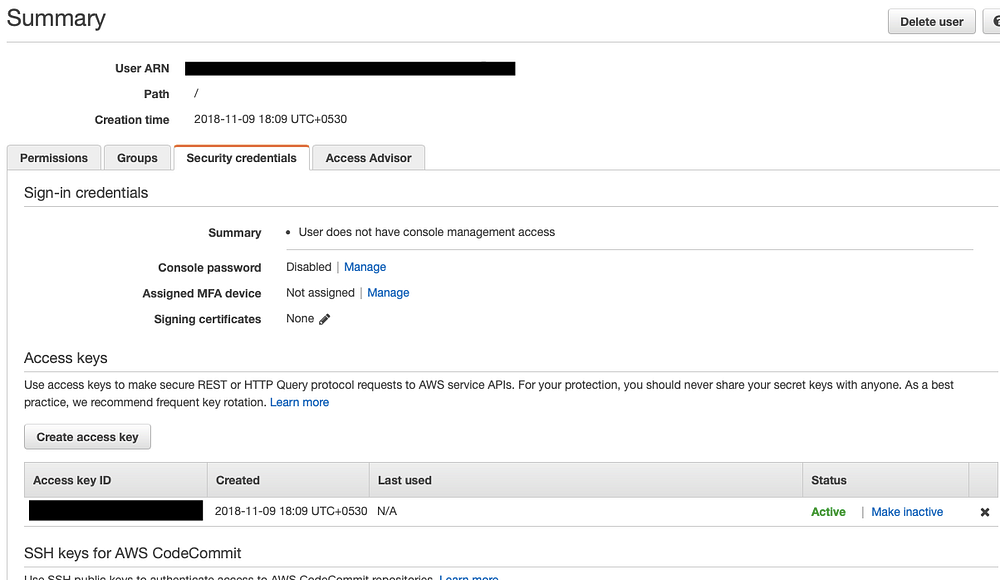
After installing the serverless dependency as a global package, you are ready to create your first function. To start, you will need to configure your AWS registered user credentials. AWS gives you a link to download access keys when creating a user.

You can also visit your username and visit Security Credentials like below.
Now let us configure AWS with the serverless package.
sls config credentials --provider aws --key ACCESS_KEY --secret SECRET_KEY
If the above command runs successfully you will get a success message like below

The good thing about using serverless npm package is that it comes with pre-defined templates that you can create in your project using a command and also creates a basic configuration for us that is required to deploy our Lambda function. To get started, I am going to use aws-nodejs template inside a new directory.
sls create -t aws-nodejs -p aws-serverless-demo && cd aws-serverless-demo
The -p flag will create a new directory with name aws-serverless-demo. The -t flag uses the pre-defined boilerplate. The result of this will create three new files in your project directory.
- Usual
.gitignore handler.jswhere we will write our handle functionserverless.ymlcontains the configuration
The default handler file looks like below.
'use strict';
module.exports.hello = async (event, context) => {
return {
statusCode: 200,
body: JSON.stringify({
message: 'Go Serverless v1.0! Your function executed successfully!',
input: event
})
};
// Use this code if you don't use the http event with the LAMBDA-PROXY integration
// return { message: 'Go Serverless v1.0! Your function executed successfully!', event };
};
In the above file, hello is the function that has two parameters: event, and context. module.exports is basic Nodes syntax as well as the rest of the code. You can clearly see it also supports ES6 features. An event is an object that contains all the necessary request data. The context object contains AWS-specific values. We have already discussed it before. Let us modify this function to our needs and add a third parameter called thecallback. Open handler.js file and edit the hello function.
'use strict';
module.exports.hello = (event, context, callback) => {
console.log('Hello World');
callback(null, 'Hello World');
};
The callback function must be invoked with an error response as the first argument, in our case it is null right now or a valid response as the second argument which is currently sending a simple Hello World message. We can now deploy this handler function using the command below from your terminal window.
sls deploy
It will take a few minutes to finish the process. Our serverless function gets packed into a .zip file. Take a notice at the Service Information below. It contains all the information what endpoints are available, what is our function, where it is deployed and so on.
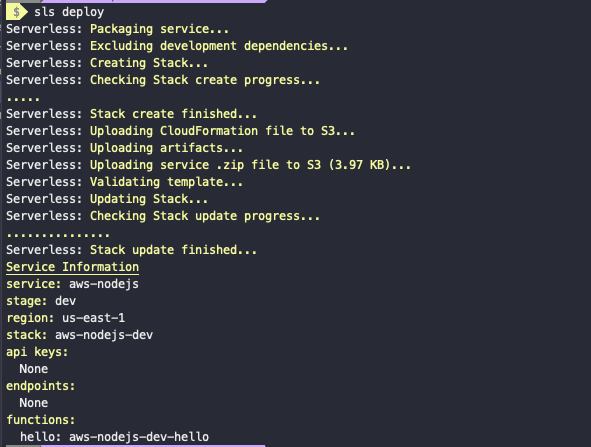
You can try the invoke attribute like following to run the function and see the result.
sls invoke --function hello
The output will look like below.

Take a look at the configuration in serverless.yml.
# Welcome to Serverless!
#
# This file is the main config file for your service.
# It's very minimal at this point and uses default values.
# You can always add more config options for more control.
# We've included some commented out config examples here.
# Just uncomment any of them to get that config option.
#
# For full config options, check the docs:
# docs.serverless.com
#
# Happy Coding!
service: aws-nodejs # NOTE: update this with your service name
# You can pin your service to only deploy with a specific Serverless version
# Check out our docs for more details
# frameworkVersion: "=X.X.X"
provider:
name: aws
runtime: nodejs8.10
# you can overwrite defaults here
# stage: dev
# region: us-east-1
# you can add statements to the Lambda function's IAM Role here
# iamRoleStatements:
# - Effect: "Allow"
# Action:
# - "s3:ListBucket"
# Resource: { "Fn::Join" : ["", ["arn:aws:s3:::", { "Ref" : "ServerlessDeploymentBucket" } ] ] }
# - Effect: "Allow"
# Action:
# - "s3:PutObject"
# Resource:
# Fn::Join:
# - ""
# - - "arn:aws:s3:::"
# - "Ref" : "ServerlessDeploymentBucket"
# - "/*"
# you can define service wide environment variables here
# environment:
# variable1: value1
# you can add packaging information here
#package:
# include:
# - include-me.js
# - include-me-dir/**
# exclude:
# - exclude-me.js
# - exclude-me-dir/**
functions:
hello:
handler: handler.hello
# The following are a few example events you can configure
# NOTE: Please make sure to change your handler code to work with those events
# Check the event documentation for details
# events:
# - http:
# path: users/create
# method: get
# - s3: ${env:BUCKET}
# - schedule: rate(10 minutes)
# - sns: greeter-topic
# - stream: arn:aws:dynamodb:region:XXXXXX:table/foo/stream/1970-01-01T00:00:00.000
# - alexaSkill: amzn1.ask.skill.xx-xx-xx-xx
# - alexaSmartHome: amzn1.ask.skill.xx-xx-xx-xx
# - iot:
# sql: "SELECT * FROM 'some_topic'"
# - cloudwatchEvent:
# event:
# source:
# - "aws.ec2"
# detail-type:
# - "EC2 Instance State-change Notification"
# detail:
# state:
# - pending
# - cloudwatchLog: '/aws/lambda/hello'
# - cognitoUserPool:
# pool: MyUserPool
# trigger: PreSignUp
# Define function environment variables here
# environment:
# variable2: value2
# you can add CloudFormation resource templates here
#resources:
# Resources:
# NewResource:
# Type: AWS::S3::Bucket
# Properties:
# BucketName: my-new-bucket
# Outputs:
# NewOutput:
# Description: "Description for the output"
# Value: "Some output value"
REST API with Serverless Stack
In this part of the tutorial, I will show you how to hook up a MongoDB database as a service to a Serverless REST API. We are going to need three things that will complete our tech stack. They are:
- AWS Lambda
- Node.js
- MongoDB Atlas
We already have the first two, all we need is to setup a MongoDB cloud database called Atlas. MongoDB Atlas is a database as a service developed by the team behind the MongoDB itself. Along with providing a free/paid tier for storing your data on the cloud, MongoDB Atlas provides a lot of analytics that is essential to manage and monitor your application. MongoDB Atlas does provide a free tier that we will be using with our serverless stack.
Creating a database on MongoDB Atlas
We will start by creating a database on the MongoDB Atlas. Login to the site and create an account if you do not have it already. We just need a sandbox environment to get hands-on experience so we must opt for free tier. Once you have your account set up, open up your account page and add a new organization.
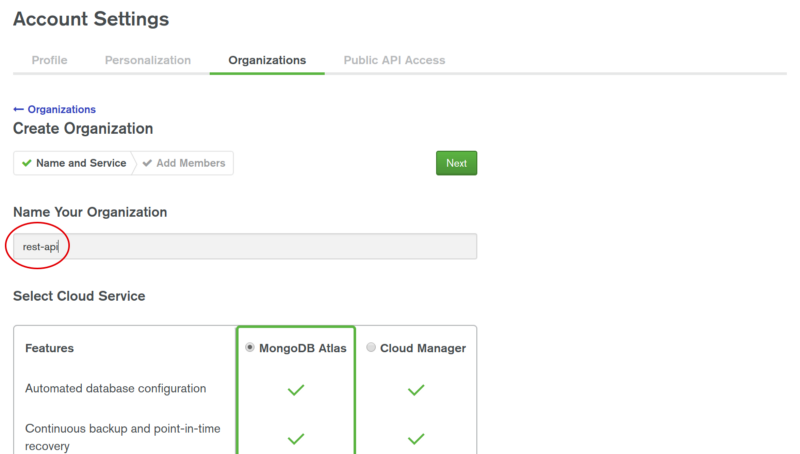
Now, after entering the name, proceed further and click on Create Organization.
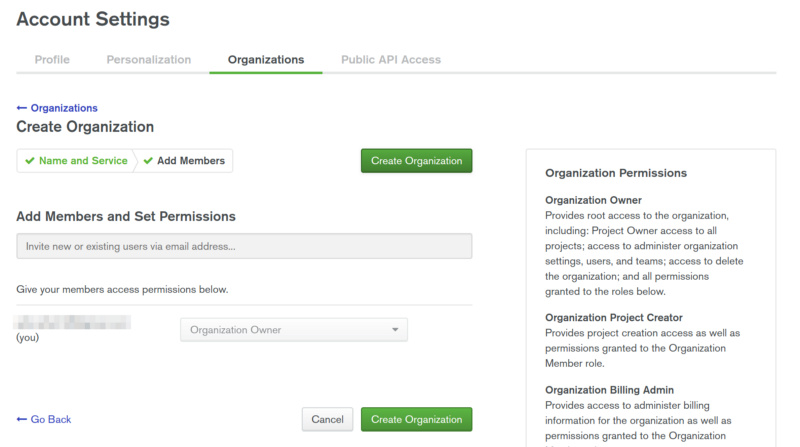
You will be then prompted to the main screen where you can create a new project. Type in the name of your project and proceed further.
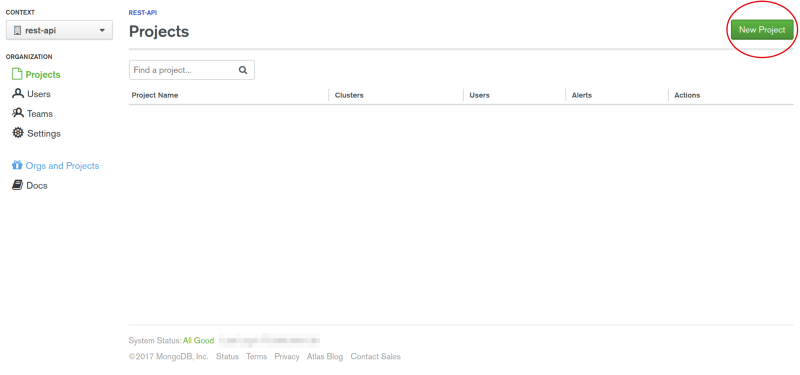
MongoDB Atlas is secured by default. You need to set permissions before we leverage its usage in our app. You can name the database at the pointed field below.
Now, we can add our free sandbox to this project. It is called a cluster.
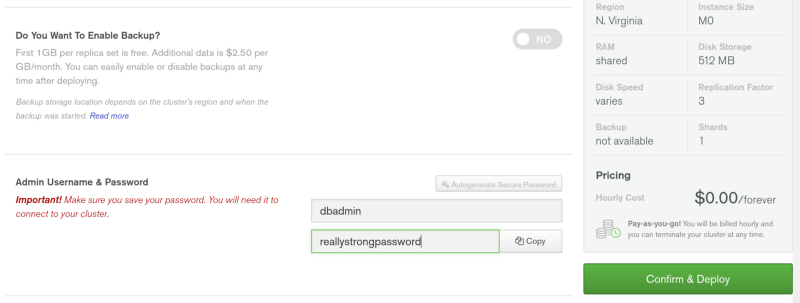
After all that, just add an admin user for the cluster and give him a really strong password. As you can see the price for this cluster will be $0.00forever. Your cluster will take a few minutes to deploy. While that is underway, let us finally start writing some code.
Building the API
Next, we install all the necessary dependencies in order to create the API.
init -y npm i --save mongoose dotenv
After that, we configure the serverless.yml and add the other handler functions that we need to deploy.
# Welcome to Serverless!
#
# This file is the main config file for your service.
# It's very minimal at this point and uses default values.
# You can always add more config options for more control.
# We've included some commented out config examples here.
# Just uncomment any of them to get that config option.
#
# For full config options, check the docs:
# docs.serverless.com
#
# Happy Coding!
service: aws-nodejs # NOTE: update this with your service name
# You can pin your service to only deploy with a specific Serverless version
# Check out our docs for more details
# frameworkVersion: "=X.X.X"
provider:
name: aws
runtime: nodejs8.10
functions:
hello:
handler: handler.hello
create:
handler: handler.create # point to exported create function in handler.js
events:
- http:
path: notes # path will be domain.name.com/dev/notes
method: post
cors: true
getOne:
handler: handler.getOne
events:
- http:
path: notes/{id} # path will be domain.name.com/dev/notes/1
method: get
cors: true
getAll:
handler: handler.getAll # path will be domain.name.com/dev/notes
events:
- http:
path: notes
method: get
cors: true
update:
handler: handler.update # path will be domain.name.com/dev/notes/1
events:
- http:
path: notes/{id}
method: put
cors: true
delete:
handler: handler.delete
events:
- http:
path: notes/{id} # path will be domain.name.com/dev/notes/1
method: delete
cors: true
The CRUD operations that will handle the functionalities of the REST API are going to be in the file handler.js. Each event contains the event information of the current event that will be invoked from the handler.js. In the above configuration file, we have defined each CRUD operation along with an event and the name. Also notice, when defining the events in above file, we are associating an HTTP request with a path that is going to be the endpoint of the CRUD operation in the API, the HTTP method and lastly, cors option.
I am going to demonstrate a simple Note taking app through our REST API. These CRUD operations are going to be the core of it. Since our API is going to be hosted remotely, we have to enable Cross-Origin Resource Sharing. No need to install another dependency on that. Serverless configuration file has support for it. Just specify in the events section like cors: true. By default, it is false.
Defining the Handler Functions
If you are familiar with Node.js and Express framework you will notice there is little difference in creating a controller function that leads to the business logic of a route. The similar approach we are going to use to define in each handler function.
'use strict';
module.exports.hello = (event, context, callback) => {
console.log('Hello World');
callback(null, 'Hello World');
};
module.exports.create = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
connectToDatabase().then(() => {
Note.create(JSON.parse(event.body))
.then(note =>
callback(null, {
statusCode: 200,
body: JSON.stringify(note)
})
)
.catch(err =>
callback(null, {
statusCode: err.statusCode || 500,
headers: { 'Content-Type': 'text/plain' },
body: 'Could not create the note.'
})
);
});
};
module.exports.getOne = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
connectToDatabase().then(() => {
Note.findById(event.pathParameters.id)
.then(note =>
callback(null, {
statusCode: 200,
body: JSON.stringify(note)
})
)
.catch(err =>
callback(null, {
statusCode: err.statusCode || 500,
headers: { 'Content-Type': 'text/plain' },
body: 'Could not fetch the note.'
})
);
});
};
module.exports.getAll = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
connectToDatabase().then(() => {
Note.find()
.then(notes =>
callback(null, {
statusCode: 200,
body: JSON.stringify(notes)
})
)
.catch(err =>
callback(null, {
statusCode: err.statusCode || 500,
headers: { 'Content-Type': 'text/plain' },
body: 'Could not fetch the notes.'
})
);
});
};
module.exports.update = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
connectToDatabase().then(() => {
Note.findByIdAndUpdate(event.pathParameters.id, JSON.parse(event.body), {
new: true
})
.then(note =>
callback(null, {
statusCode: 200,
body: JSON.stringify(note)
})
)
.catch(err =>
callback(null, {
statusCode: err.statusCode || 500,
headers: { 'Content-Type': 'text/plain' },
body: 'Could not fetch the notes.'
})
);
});
};
module.exports.delete = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;
connectToDatabase().then(() => {
Note.findByIdAndRemove(event.pathParameters.id)
.then(note =>
callback(null, {
statusCode: 200,
body: JSON.stringify({
message: 'Removed note with id: ' + note._id,
note: note
})
})
)
.catch(err =>
callback(null, {
statusCode: err.statusCode || 500,
headers: { 'Content-Type': 'text/plain' },
body: 'Could not fetch the notes.'
})
);
});
};
The context contains all the information about the handler function. How long it has been running, how much memory it is consuming among other things. In above, every function has the same value of context.callbackWaitsForEmptyEventLoop set to false and starts with connectToDatabase function call. The context object property callbackWaitsForEmptyEventLoop value is by default set to true. This property is used to modify the behavior of a callback.
By default, the callback will wait until the event loop is empty before freezing the process and returning the results to the invoked function. By setting this property’s value to false, it requests the AWS Lambda to freeze the process after the callback is called, even if there are events in the event loop. You can read more about this context property at the official Lambda Documentation.
Connecting MongoDB
We need to create a connection between the database and our serverless functions in order to consume the CRUD operations in real-time. Create a new file called db.js in the root and append it with following.
const mongoose = require('mongoose');
mongoose.Promise = global.Promise;
let isConnected;
module.exports = connectToDatabase = () => {
if (isConnected) {
console.log('=> using existing database connection');
return Promise.resolve();
}
console.log('=> using new database connection');
return mongoose.connect(process.env.DB).then(db => {
isConnected = db.connections[0].readyState;
});
};
The is common Mongoose connection that you might have seen in other Nodejs apps if using MongoDB as a database. The only difference here is that we are exporting connectToDatabase to import it inside handler.js for each CRUD operation. Modify handler.js file and import it at the top.
'use strict';
const connectToDatabase = require('./db');
Next step is to define the data model we need in order for things to work. Mongoose provides this functionality too. Serverless stack is unopinionated about which ODM or ORM you use in your application. Create a new file called notes.model.js and add the following.
const mongoose = require('mongoose');
const NoteSchema = new mongoose.Schema({
title: String,
description: String
});
module.exports = mongoose.model('Note', NoteSchema);
Now import this model inside handler.js for our callbacks at the top of the file.
const Note = require('./notes.model.js');
Using Dotenv and Environment Variables
Protecting our keys and other essentials is the first step to a secured backend application. Create a new file called variables.env. In this file, we will add our MONGODB connection URL that we have already used in db.js as a process.env.DB. The good thing about environment variables is that they are global to the scope of the application.
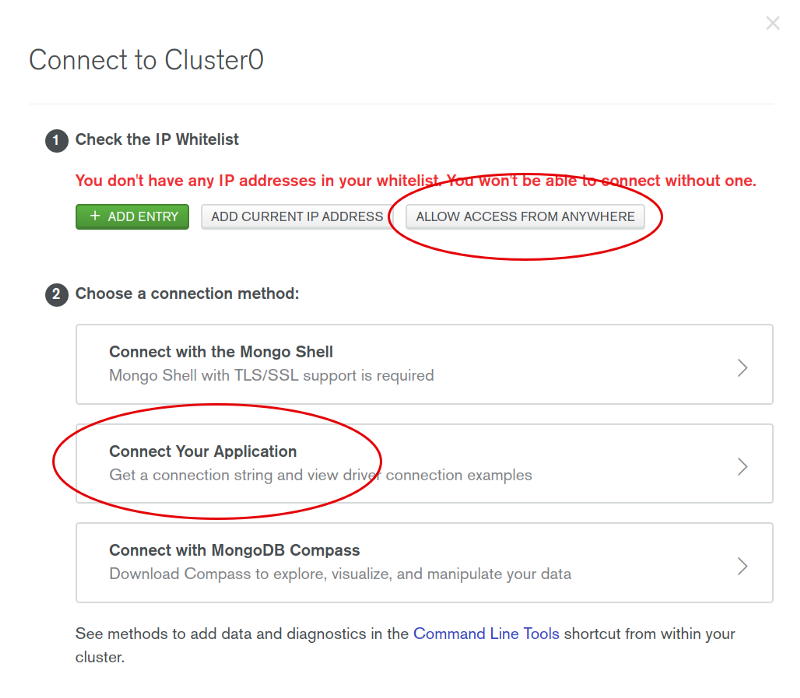
To find out our MongoDB URL, we need to go back to the mongodb atlas, to out previously created cluster. Click the button Connect and then you will be prompted a page where you can choose how to access the application. Click Allow Access From Anywhere.
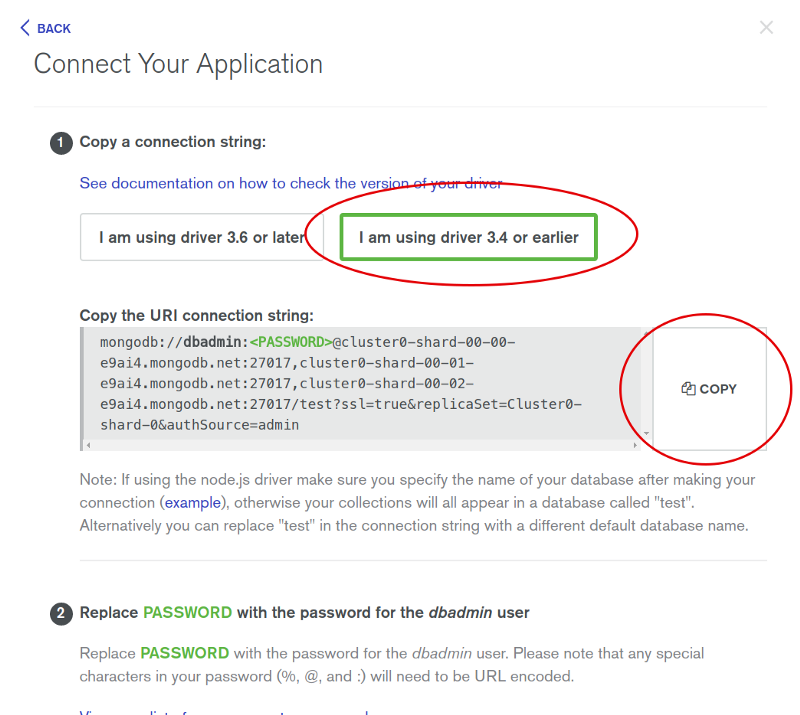
Copy the mongodb URL from above and paste it in the variables.env file.
DB=mongodb://<user>:<password>@cluster0-shard-00-00-e9ai4.mongodb.net:27017,cluster0-shard-00-01-e9ai4.mongodb.net:27017,cluster0-shard-00-02-e9ai4.mongodb.net:27017/test?ssl=true&replicaSet=Cluster0-shard-0&authSource=admin
Replace the user and password field with your credentials. Now to make it work, all we have to add the following line in our handler.js.
require('dotenv').config({ path: './variables.env' });
Deployment
All you have to do is run the deploy command from the terminal.
sls deploy
Since we have connected our Lambda function, this command will prompt us with a different endpoints. Each handler function is deployed as a separate REST endpoint.

You can test your API using CURL command from the terminal like below.
curl -X POST https://7w3e8tfao0.execute-api.us-east-1.amazonaws.com/dev/notes --data '{"title": "My First Note", "description": "This is a note."}'
You can find the complete code for this article in the below Github Repository ?
Starting a new serverless project, or looking for a Node developer?
Crowdbotics helps business build cool things with Node (among other things). If you have a Node project where you need additional developer resources, drop us a line. Crowbotics can help you estimate build time for given product and feature specs, and provide specialized Node developers as you need them. If you’re building with Node, check out Crowdbotics.
Thanks to William Wickey for help editing.
Aman Mittal
??Fullstack Developer ❤️ Nodejs ReactNative | ? Blogger & Author | Subscribe ?https://upscri.be/e51a31/⚛️ + ?
Crowdbotics
Turn ideas and specs into working code.