If you’re not a developer but responsible for the performance of developers, you might want to skip way way down to “The upside down” section.
Go!

A long meandering intro
When I speak to people about fast development (and I do, often) some people display a peculiar desire to translate the concept of fast into fast initially, but in a shortsighted way, so actually, slow.
It’s tempting to attribute this tendency to NND (Negative Nelly Disorder), but I think it goes deeper than that, and further back; I blame the famous fable of The Tortoise and the Hare.
This is a story in which an erratic rabbit and a tortoise with a purpose battle it out until a conclusion is reached:
Slow and steady wins the race
This is a reassuring message for (slow) children, but I propose the introduction of a new element to this fable, and I humbly present it to you now: The Tortoise, the Hare, and the Herd of Buffalo.
In this variation of the tale, the hare and the tortoise are busy hip hopping over one another when on the horizon appears an unstoppable wall of thundering buffalo. The buffalo storm past in a cloud of hooves and productivity to win the race. The moral of this revised story will be:
Fast and steady wins the race
Epilogue: the hare and tortoise were trampled to death. Their remains were turned into a creamy chowder and fed to the crowd from a tortoiseshell bowl. (Fun fact: after Charles Darwin documented the existence of the magnificent Galapagos tortoise, he took a couple with him as a snack to eat on the way home. Fact.)
So, we’ve established that ‘fast and steady’ beats ‘slow and steady’ every time.
But there’s some bad news…
The world favours those who move slow
Have you even walked down a crowded footpath in a hurry? Bobbing and weaving through the crowd, scanning for overtaking opportunities, side-stepping the oblivious phone gazers.
Imagine the path you weave, if viewed from above — a complicated, twisted line.
Contrast that to those who move the slowest. They don’t need to take the fast people into account, they only need to worry about themselves, plodding forward in a perfectly straight, simple line.
Slow is the default. Slow is easy. Fast is hard.
What this post is really about
This post is actually about happiness. Seriously. I only used the word ‘fast’ in the title as click-bait for those who wanted to come and tell me that ‘fast’ is actually ‘slow’.
When you are faster, when you are more productive, you will feel proud of what you have achieved, proud of this thing you spend a third of your life doing.
You must have experienced this at least once: that feeling when everything came together on a day and you really got shit done. Maybe it was writing code, or gardening, or fixing something on your car. Whatever it was, you went to bed with a warm sense of accomplishment.
That feeling is important, says me, and a worthy goal.
Oh and also, if you’re faster, you’re worth more money, and money is the root of all happiness.
Let’s begin with the nuggets of advice…
1. Measure how you spend your time
Short version
Get some software that can record and report to you where you spend your time. It might just provide you with the motivation to cut back on the short-term temptations that don’t pay off.
Long version
The first step to faster development is to get organised about time. And the first step to getting organised is to measure.
There are lots of tools out there to track where you’re spending your time. I use one called RescueTime which is not bad. It records open application windows and URLs and I can group these into activities. Here I can see where I’m spending my time each day:
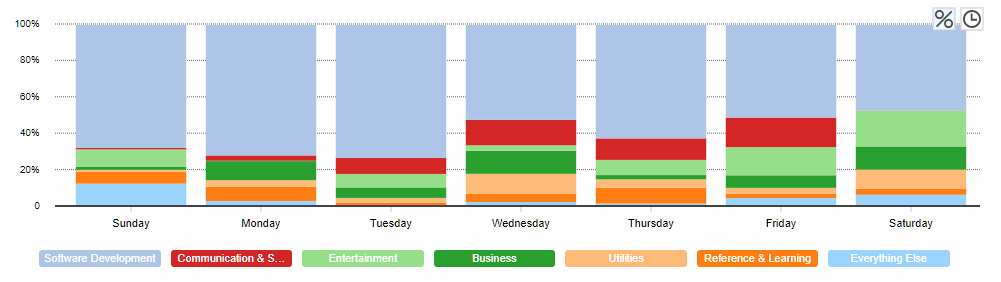
What you’re looking for with tools like this are actionable metrics. Information that makes you think I need to change that.
For me, it raises questions like: “Did I really spend 2 hours in Slack yesterday? Could it have been less?” It also revealed to me that sometimes I will spend hours in Jira (writing and refining requirements for tasks), when ideally a professional requirements-writer would be doing that (I’ll address this further in section 8: Make some noise).
Personally, I used the app for a few weeks, got a feel for areas I could improve, and it’s been of limited use since.
2. Stop multitasking
Short version
Chunk your coding time into distraction-free sessions of at least 30 minutes. 2 hour sessions are the best.
Long version
We’re getting into obvious-self-help territory here, but I think it’s worth elaborating on since it makes such a big difference, and so few people do it.
Let’s assume that on a given day, there is a fixed amount of time that you’ll spend writing code — the rest of it spent talking to co-workers, emails, meetings, and all the other fluff. How you go about organising this time can make an enormous difference to how much you get done in that day.
Below are two timelines involving the same tasks, where blue is development time, and the pastels are the other things that vie for your time.


So-called multitasking is the default mode for most people. Your phone rings, you answer it. A colleague comes up to your desk, you take off your headphones to see what they have to say, a chat notification pops up on your screen and — at that moment — there is nothing more important in this world than clicking on it and reading what it has to say.
(Worst idea ever: notifications that show you a teaser of the message, to entice you even further to stop what you’re doing and switch tasks. We really do set ourselves up for failure.)
When we’re ‘multitasking’, our response time to any new demand for our attention is fast, so we feel good. We are multitasking. We are being productive!
But of course, we aren’t. Multitasking is very unproductive. And this is doubly true when it comes to writing code.
The activity of writing code is special because it requires hefty usage of short-term memory. It’s full of little strings of letters like parseResults() that can represent hundreds lines of code. If you haven’t memorised what parseResults does, you need to go and look at it to comprehend what the code is doing, which is slow. If you have memorised what it does, then you can move a lot faster. It’s similar to the difference between reading from disk and reading from RAM.
Consider this snippet:
const rawResults = await goGetResults();
const results = parseSortAndFilterResults(rawResults);
if (status === 'READY') {
render(results);
} else {
messages.on('ready', data => render(data.results));
}
If you’re not familiar with any of this you’d need to find out what goGetResults does, then what parseSortAndFilterResults does, what that result object contains. Then understand what status is, when and where it can be changed. And where can that ‘ready’ event be triggered from and what’s the payload it’s called with? And so on.
When you first sit down to work on the code, you will jump about the place to familiarise yourself. Over 5, 10, 15 minutes you’ll load more and more logic into your short-term memory and your magnificent brain will begin to build a map of the logic landscape.
Things begin to flow. You’re in the zone.
And then your phone rings.
You answer it, you speak about important things. When you return to the code you discover that your brain has done a garbage collection and some information is lost. Stupid volatile memory.
Now you need to go bouncing around the codebase again — loading once more from disk into RAM. It takes maybe 5 minutes of jogging your memory and you’re back into flow.
Then a Slack notification pops up.
Then an email, then a colleague taps you on the shoulder, then a text message, and on and on.
My advice is exactly what you think it is, but to be specific: at a minimum, aim for 30 minute chunks of work where all you do is write code. Set a timer.
Put your phone in airplane mode (science says put it in a different room). Close every app on your computer that throws up notifications. Although both macOS and Windows have “do not disturb” modes, I find that even the visual indicator of new activity in a browser tab or app icon can nibble away at my attention, so I prefer to close tabs and apps entirely.
If you’re a lifelong multitasker, simply squeezing in two or three 30-minute sessions a day will make a noticeable difference.
If you get to the end of 30 minutes, do a little stretch, and think you can carry on without first checking your emails/texts/chats/twitter, then DO IT, before that garbage collection happens.
30 minutes is good, but two hour chunks are The Good Stuff. Depending on the week, I’ll maybe get three or four of these sessions in. 9:30–11:30 AM works well for me. You can go all out and put these focus sessions in your calendar — and if you’re getting right into this productivity thing, you should go and read Deep Work by Cal Newport.
A few more words about notifications, because I discovered something about a year ago and it has made a big difference to my productivity.
I don’t have notifications. At all, anywhere. My phone doesn’t have a ringtone. I don’t get notifications for new emails, chats, or tweets — on my phone or my computer. Ever.
I think of all digital communication now as I think of my analogue communication (my letter box). I’ll check it when I want to check it. My work email, I check in the morning then close it for they day. I leave Slack open outside of focus sessions, especially when working from home, but with no notifications.
With the phone, an interesting thing has happened: since it never has a little envelope or speech bubble icon on it telling me something is awaiting my attention, my attention never drifts to my phone screen. It took a few weeks, maybe months, but I no longer obsessively tap my phone or look at the screen when I pick it up to see if anything is there to distract me, because there never will be. I no longer imagine, out of the corner of my eye, that my phone has just lit up with a twitter notification when really it’s just a reflection of a bird outside the window.
One thing that I had to consciously do was reject the concept of ‘urgent’. If you believe in urgent you will have trouble disallowing digital devices from dictating when you must pay attention to them.
If you’d like to break free of this concept of urgent, here’s a fun exercise: make a note of things that happen that you consider urgent and store them away. Then at the end of each month read back through these and ask yourself “would it have been catastrophic if I had seen that message 25 minutes later?” If you have examples of this, please share with the rest of us in the comments, you must have a pretty exciting life!
A final note about making yourself less-accessible to others during these focus sessions: there is a balance to be found between productivity and selfishness. I will go easy on the focus sessions during times where that would be detrimental to the team. Obviously you need to find a balance that works for you.
3. Task chaining
Short version
Do you move seamlessly from one task to the next? If you’re losing time in between, it might be a clash between git and agile processes.
Long version
I work predominantly in terms of discrete tasks (e.g. Jira tickets, GitHub issues). These are planned chunks of work that can be picked up, worked on in a git feature branch, then merged back to master.
So there are two things at play most of the time: the task, and how its scope was defined, and the git processes used to actually do the work and ship it to production.
If done wrong, this can be a persistent productivity drain.
An example: imagine it is a few years ago and I am going to implement the Medium clap button, replacing the old single-click heart button. It has been decided that this should be split into two tasks, one to convert to a new API that accepts a number of claps, then another to update the UI from a heart to the new clappy hand.
I complete the API task on a clap-api feature branch, and create a pull request. This might take a day or two to get through code review and QA and into the master branch. In the meantime, I start the UI task. But to do this I need to use the code that currently only exists in the clap-api branch.
One approach is to simply create the clap-ui branch off of clap-api — I will then have that code and can continue on. The clap-api branch will get merged to master soon, then clap-ui will follow shortly after and the task pair will be done.
Zero downtime between tasks. Nice.
This will work just fine a lot of the time. But every now and then you will hear a noise over your shoulder, turn around, and git will kick you in the face.
That is, if you follow one of two common git practices: rebasing or squashing.
This scenario might be a bit hard to follow, but if it sounds familiar you’ll know you’ve wasted time on this: if I create clap-ui from clap-api, then I will have commits that were created as part of the API branch in the UI branch (when viewed as a diff with master). Then if I rebase the clap-api branch (which destroys commits), or squash and merge it into master (which destroys commits), I will be left with commits in the clap-ui branch that contain changes that were not done in that branch. Now, if another developer changes one of the files that was changed in one of these commits, I will have a problem. As far as git is concerned, I want to change that file too, because I have a commit in my branch that says so. Sometimes this will result in an unnecessary conflict, but worse, sometimes it will simply override the other developer’s change, and if that makes it through quality checks, then I’ve got myself a bug in production.
And so, I eventually learned to never branch off of anything other than master — to be safe from time-consuming conflicts and bugs.
In the API/UI example, I would finish the API task and then wait until it was merged before starting on the UI task. In the meantime I’d do some other task that needed doing. Maybe being forced to drag something into the sprint because all other tasks were blocked waiting for the API task to go in.
None of this resembles moving ever forward like a powerful herd of buffalo. It seems more like hare behaviour.
I worked this way for years (either spending time on unnecessary conflicts or being blocked waiting for tasks to merge) and never really considered how I could improve the situation. It never occurred to me that destroying git commits was the root of so much friction.
The turning point was moving to a new job where they do things differently. Here I realised hey, the way you guys do git is making me much more productive. This is my idea now.
This new approach removes all these friction points and I’d love to tell you all about it. I don’t destroy commits anymore. If a commit is created on a branch, that commit will eventually end up in master. No squashing, no rebasing.
Step one — and you’re not going to like step one — is to not give a shit about your commit history in master. Here’s the site I’m currently working on…
The ‘downsides’ are obvious: your commits in master are no longer a form of ‘release notes’ — you wouldn’t do this in public source code. You can’t use git bisect because most commits aren’t even working code. Although I’d suggest that if you even know what git bisect is, maybe you’re allowing a few too many bugs into master in the first place.
There’s not much else to it. Commit as you do your work. Put the task code in the commit names so it shows in git blame, and never squash or rebase. If you want code from another branch, merge it in. If you want code from three other open branches, merge ’em all in! Those commits will show in your branch (when diffing with master) until the other branch is merged, then it’s clear sailing.
I’m well aware of how unappetising this will seem to many of you, but if changing the way you work will improve your productivity, my advice to you is to think about what you value more, your productivity or the cleanliness of your commit history.
Agile done poorly is bad for productivity
While we’re on the topic of tasks … in some places I have worked, I have seen two interesting practices enforced in the name of ‘agile development’ that are bad for productivity.
The first is alluded to above, the belief that tasks should be broken down into the tiniest of chunks — some even say if you can’t finish a task before the sun sets, it’s too big. If you do this and it doesn’t negatively affect your productivity, that’s great. But if it does, you gotta ask, why are you doing it?
The second is specific to Scrum, and it’s the idea that once you’ve started a sprint, you should not add any tasks to it. The idea is that rather than add more tasks to the sprint, idle developers should busy themselves with tech debt or documentation or (sigh) ‘help someone else out’ with their task.
This is illogical and harmful to productivity, and it’s based on the greatest misunderstanding in the world of Scrum…
Whether or not you finish the tasks you planned for a sprint is a result of how accurately you estimated tasks, not how much work you got done. Finishing early just means you were too pessimistic during estimation. Not finishing all tasks just means you were too optimistic. It has nothing at all to do with how well the team performed during the sprint.
The idea that finishing all the tasks in a sprint is good and not finishing them is bad is silly and counterproductive. At best it simply encourages pessimistic estimation. At worst it breeds a culture that rewards committing to doing less.
(I’m feeling ranty now, so I’ll go further and say that the number of story points you complete during a sprint also has nothing to do with how much you achieved. Any variation in ‘velocity’ between sprints represents a variation in the accuracy of the estimation of the tasks in that sprint. The sentiments of “good work team, we did 45 points this sprint!” or a solemn “we only got through 37 points” are equally nonsensical. A sensible comment would be: “our velocity this sprint was within 20% of the previous sprint, well done team on your consistent estimation in the face of many unknowns — this will help us plan out future work more accurately”.)
OK, I have gotten somewhat off topic, but I would wrap this up as a double-question: are your Agile/Scrum practices resulting in you doing less work? If yes, WTF?
4. Do things once
Short version
Don’t write bugs.
Long version
Imagine our herd of buffalo, thundering along like a herd of buffalo, when one of them drops his lip balm. Now he’s gotta stop and turn, bumping his way through the rest of the herd muttering ‘sorry, oops, watch out, sorry, excuse me’ to backtrack and ensure the future moistness of his lips.
Silly buffalo, slowing down the whole team.
Every minute you’re fixing bugs, you’re pushing backwards through the crowd and doing serious damage to your productivity.
I believe that it’s possible to never ship a bug to production.
And I choose to believe this (despite copious evidence to the contrary) because as soon as I buy a t-shirt that says “bugs happen”, I’m giving myself permission to not aim for a zero-bug track record.
So for the last few years, for each bug found that is my fault, I do a personal root cause analysis, to try and find something in my approach to writing code that I can fix.
Two things I have noted as a result of doing this, with some embarrassment:
- When I’ve been almost done with a task for days and I’m itching to move on to the next thing, I tend to get impatient. So I might make one final little refactor, but then cut corners and not re-test the entire thing.
- Same as ‘1’, but I’m the reviewer. Someone else is making that final little change and then I fail to re-review the entire pull request as a whole. (If I let a bug through code review I might as well have created it myself).
To avoid these lazy, avoidable bugs, I have followed the following rule for the last few years: I never ever go straight from typing code to creating a PR.
I go for a walk instead. Around the block, around the office, around the maypole, whatever. I switch contexts to something other than code for a minute or two.
Then, as I return to my chair, I transform into my worst critic, hell bent on breaking that new feature that Idiot David just wrote. In order to find flaws in Idiot David’s work, I have two angles of attack.
First, some exploratory testing, drilling into all the interactions that I know are most vulnerable, anything that had been tricky to implement, poking at all the edge cases, launching it on the most obscure of supported devices, inputting weird characters and super-long strings. That sort of thing.
Second, I will go though the branch diff on GitHub/BitBucket line by line and imagine it was written by a developer that I really don’t like at all (not so far from true, I suppose). This must be done in the online diff tool, because there’s something about seeing those green and red backgrounds that turns me into a really picky bastard. I will laugh with glee when I find that Idiot David left in a commented out line of code or was inconsistent with his variable nomenclature.
I reckon in 80% of self-code-reviews I’ve done over the last few years (one for every branch) I have found something to fix. These are silly little mistakes that a colleague would have found, then typed a PR comment, then I would have read it, then fixed it, then type ‘fixed’ then let them know that the branch is ready for a re-review. It saves so much time for me to find those little mistakes myself.
My goal now is zero-comment pull requests. Of course it doesn’t always happen — there’s more to PRs than silly mistakes — but simply aiming for that makes a big difference in my efforts to move like the buffalo.
So, the next time you create a PR, when you’ve got the diff on the screen and you’re just about to hit the ‘create pull request’ button, go get a glass of water, stretch your arms and wiggle your toes. Then read through the diff as though you’re really trying to find mistakes.
5. Identify and fix your slow points
Short version
Ask yourself which coding activities repeatedly take you longer than you think they should. Identify and dedicate some time to skilling up in those areas.
Long version
This can be tricky. How can you know if you’re slower at something than you should be? Sometimes it’s only when you see someone else do something twice as fast as you that you realise there’s a better way. The first time I saw someone use the performance tab of the Chrome DevTools it blew my mind, so I went and read all of the docs.
(“Know your tools” could be its own section, but really there’s not much to expand on. Know your tools.)
To kick off this introspection, when you complete your next task, take a few minutes to think about where you spent your time. Does anything stand out? Did you spend three hours trying to get a word and an icon to vertically align in CSS? Maybe you got bogged down guessing-and-checking glob syntax, deciphering a regex, or scratching your head over FULL RIGHT INNER OUTER JOINs.
Is there perhaps something going on there that you don’t truly understand?
CSS is particularly problematic because it seems to be the number one thing that people think they can use without ever reading the manual. Which is nuts, because CSS is three times the size of JavaScript and even in 2019 suffers from rage-inducing levels of inconsistency between browsers.
(I made up the ‘three times’ part — don’t believe everything you read.)
When you have identified something you suspect you’re spending too much time on, you can ask yourself: if I’m going to be doing this job for many years to come, is taking the time to deeply understand this concept going to pay off?
The answer is probably yes, so bite the bullet and RTFM.
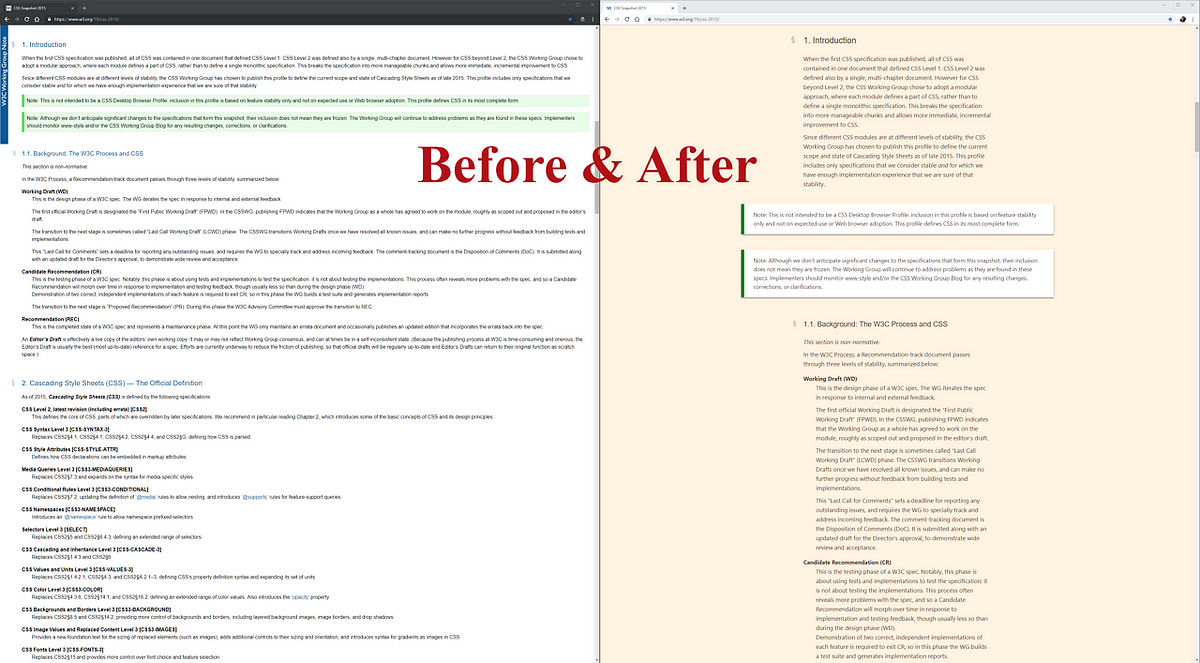
Shameless plug: most web specs look super-gross so I wrote a Chrome extension to make ’em look pretty.
I wrote another one that remembers the scroll position for a page, handy for those massive long specs that you’re reading for 30 minutes a day.
Another sign you might have some learnin’ to do is when you find yourself thinking that an application is behaving in a ‘weird’ or ‘random’ way.
Computers aren’t weird and random, humans are. If you don’t understand why something is happening, it might indicate there’s something for you to learn that will increase your productivity.
For a long time I spent the first hour of every day reading, focusing on the things I struggled with the most. I would get in at 7 AM, read till 8 AM, without exception. I highly recommend it; you will notice yourself getting faster and faster quite soon, and it will continue as long as you keep up the reading.
Of course, I don’t do this anymore because I know everything now.
6. Structure first, then polish
Short version
For any given task, sort out the big stuff first. Work out how you’re going to organise your code, and if necessary, try a few different things before settling on the best approach.
Resist the urge to apply polish (UI style, code style, tests) until you’re pretty sure this structure won’t be changed.
Long version
Deleting code is a natural part of development. We learn as we go, we think of a better approach after a good night’s sleep, we fail to take things into consideration before a moment of realisation and sometimes, once in a blue moon, requirements change while a task is in progress.
What you don’t want to do is write some code, make the UI pixel perfect, get line spacing between methods just right, add unit tests, and then realise that actually there’s a more elegant solution and you need to delete and reorganise bunch of stuff.
So, if you can separate core work — the bare minimum you need to do convince yourself you’ve found the right approach — from time spent making it perfect, then refactoring requires less effort, and you’ll be less reluctant to throw out the old code since you haven’t spent so much time on it.
If the task is complex enough, do the core work then request an initial code review (or, you know, just talk to other people about it). Don’t spend a week slaving away at something, making it perfect and polished, tested to 100%, only to put it up for code review and be told there’s a much simpler way to do it.
7. Keep one eye on the future
Short version
Don’t do things now that you’ll wish you didn’t do in the future. Write code that’s easy to refactor.
Long version
This section is about the long haul. This is difficult to wrap up into some generic ‘advice’ because it’s so dependant on the nature of the code that you’re writing.
Here’s some broad suggestions:
- Write code that’s flexible enough to continue being useful as the product changes. This usually means splitting up your code into small modules that do one thing.
- Don’t write code that’s so flexible you’re adding unused complexity. (Don’t build for tomorrow what you can build tomorrow.)
- Write code that’s easy to refactor.
That last one is probably the most difficult to do — particularly if you don’t have experience in any big refactoring projects. I’ll outline two examples, picked because they’re so prevalent, so harmful, and relatively easy to avoid: failure to separate concerns and failure to modularise CSS.
When it comes to separation of concerns, you can follow at the bare minimum a very simple rule: keep code that does different things in different files. Database operations, API calls, data manipulation, utilities, UI-rendering, all these things belong in their own files. (To repeat: this is the bare minimum, you should really put considerable time and effort into designing your application architecture.)
Most codebases will go through few a major refactors per decade. Things like replacing server-language HTML templates with JavaScript-rendered HTML, replacing SQL with NoSQL, converting a monolith to microservices.
When one of these major changes comes (and it will), you could save months of effort if the area of code you’re updating (UI, DB, API) exists in self contained files that are only concerned with that technology. It’s a pretty big payoff for a pretty small change in the way your arrange your code.
CSS gets another special mention here because of one rather awful combination of properties: being global and cascading. A single CSS rule could have been referenced anywhere in any file that outputs HTML. And it could have been combined with a rule from any other CSS file, and a class referenced on any HTML element anywhere further up the tree, to create an unfathomable dependency that will break at the slightest refactor. Oh and there are two rules that both apply, the winner selected by a specificity algorithm than includes needing to know the order in which those CSS rules are defined, after you concatenate your 82 scattered CSS files.
This really, really, quickly turns into a situation where you’re wasting significant amounts of time trying to make changes without breaking other parts of the interface.
If you’re writing CSS but you’re not writing modular CSS, I have good news for you: you’re being terribly unproductive and there are several well documented ways to dig yourself out of this hole. CSS modules are best, BEM is a perfectly acceptable alternative, as is CSS in JS (the great thing about CSS in JS is that it makes some people so angry, which is always fun to watch).
These are just two examples of small changes you can make to the way you write code that have far-reaching, positive effects. There are of course many more, so go find ‘em!
8. Make some noise
Short version
If you’re being asked to do things that are detrimental to your productivity, don’t suffer in silence, let management know.
Long version
There’s a good chance that you don’t work in a perfectly formed team. In the most organised team I’ve worked with, I got my 5 hours a day for writing code. In the least organised team is was about half that.
Imagine that, one company being able to move twice as fast as their competitors!
So, if you’re spending time on things that aren’t in the best interests of productivity, and it’s not something you can change on your own, then make some noise, tell people with the power to rectify the situation.
Ultimately, everyone’s on the same side — management care about the product, and it’s surely no mistake that product is the first part of the word productivity.
In other words, if you’ve got productivity problems, they’ve got product problems, and there’s a good chance they’d like to hear a report from the trenches if it might result in a better product.
There is one mistake that I see most companies make (perhaps they wouldn’t all agree that it’s a ‘mistake’) — and that is the idea that developers should be used to do things other than develop.
Hear me out…
The interesting thing about a development team is that you can take away all sorts of important supporting roles, and the developers will keep outputting code.
If you take away an iteration manager/scrum master, devs will pick up the slack. You can ditch your designers and developers will work out how things should look. You don’t even need a product manager/owner/BA/anyone else gathering and documenting requirements — developers will sort out the details when they’re writing code. And there’s really no need to waste money on QA (quality assurance) personnel. Just implement QA (quality assistance) — where developers do all the QA themselves — what could possibly go wrong.
Now, developers are smart flexible people, so yes they can do all of these things. But when they’re doing these things, they’re not writing code. So the company is paying for a QA, and an iteration manager and a designer and a product owner — the difference is that they’re not paying experienced professionals to do these tasks, they’re paying developers (who are not exactly the cheapest resources out there).
This hurts productivity, but I think the reason the problem is so common is that waning productivity rarely sets off alarm bells. If you’re making cars, you can read a report and ask “why did we only ship 45,000 vehicles last month?!”. But if you’re making code, the difference is hidden by the natural variability of output. No one’s yelling “why did we only ship 34.5 new buttons last month?!”
And your Agile ‘velocity’ doesn’t help either, because developers are encouraged to take into account all aspects of a task when estimating, including, QA, refining requirements, and so on. If anything, it looks like you’re getting more done, because effort that wouldn’t normally be tracked on the board suddenly gets tracked.
I suspect than when many organisations make decisions that negatively impact productivity, it’s because they don’t know that it negatively affects productivity. The only way they could know that devs can’t move full speed ahead is if the devs say so.
So, if you’re a developer, and you’re spending a significant amount of time on tasks that you think could be performed better by a trained professional, make some noise.
The upside down
I thought I’d wrap this up with a handy guide of how to create the least productive team you could possibly imagine.
- Be a close-knit tightly integrated squad. Everyone goes to all meetings. Everyone is involved in everyone else’s business. Developers go to design sessions and vice versa. Everyone goes to company strategy meetings and ‘town halls’.
Result: A single, pointless, one-hour meeting each day can reduce productivity by 12.5%. (Pro-tip: never start your meetings on time, a simple way to burn another few percent.) - Implement the devil’s triangle of task handling: tiny little tasks, a git strategy that makes it hard to springboard off the work of a previous task, and a QA process that takes a few days for a task to make it into the master branch.
Result: This can shave almost 5% off your productivity if you make your tasks small enough. Beware though, you need to do all three to reap the desired productivity damage. - Don’t waste time and money on scrum masters, product owners and other such Jira jockeys. Devs can do all that.
Result: With a team of, say, 7 developers, doing away with a single professional non-developer could reduce productivity by as much as 15%. - Be ‘iterative’. That means vaguely describe what needs to be built, let a developer spend a week writing code, then tell them what you really wanted.
Result: Persistent application of such iterations can shave off another 5–10%. - When the work that your team guessed could be done in a sprint is finished early, head to the ping pong table.
Result: If you’re finished 1 day early every second sprint, that’s another 5% of your productivity kicked to the curb. - Maximise availability. Ensure everyone has notifications turned on and up. If someone doesn’t respond to an email, go to their desk and prod them. No remote working either, everyone needs to be in the (open plan) office at all times so you can have discussions about things. Collaboration!
Result: This one’s hard to measure, but I estimate that a properly implemented regime of sustained fractured attention can inflict productivity reductions as high as 20%.
All told, if you put in the effort, you can have a team that operates at about half their potential.
But we’re not done yet, there’s a hidden bonus! With a bit of luck, this forced impotence will reduce morale, leading to higher attrition, eventually devolving into a revolving door feedback cycle, with even further reductions to productivity!
Thanks for reading, my internet friends!
Speaking of segues, do you read fiction? Do you want to read some fiction that I wrote? It’s a bit shit but maybe your sense of humour is a bit shit and you’ll like it. Go find out.
Adios, folks!
Source: https://hackernoon.com/the-fine-art-of-fast-development-f3b1abb509da
Written by
David Gilbertson
I like web stuff.
Hacker Noon
how hackers start their afternoons.